
Inspecciones de bienestar animal basadas en el riesgo de granjas de ganado vacuno y porcino

Investigar el uso de algoritmos de aprendizaje automático para respaldar inspecciones de bienestar animal basadas en el riesgo de granjas de ganado vacuno y porcino
 Vencer a Thomann1*†‡
Vencer a Thomann1*†‡ Thibault Kuntzer2†‡
Thibault Kuntzer2†‡ Gertraud Schüpbach-Regula1‡
Gertraud Schüpbach-Regula1‡ Stefan Rieder2*‡
Stefan Rieder2*‡- 1Instituto de Salud Pública Veterinaria, Facultad Vetsuisse, Universidad de Berna, Berna, Suiza
- número arábigoIdentitas AG, R&D, Berna, Suiza
En la producción ganadera, los datos relacionados con los animales a menudo se registran en bases de datos especializadas y, por lo general, no están interconectados, excepto por un identificador común. El análisis de conjuntos de datos combinados y la posible inclusión de información de terceros puede proporcionar una imagen más completa o revelar relaciones complejas. El objetivo de este estudio fue desarrollar un índice de riesgo para predecir las granjas con una mayor probabilidad de violaciones del bienestar animal, definidas como el incumplimiento durante las inspecciones de bienestar en la granja. Para ello, se optó por un enfoque basado en datos, centrándose en la combinación de las bases de datos y los registros existentes del gobierno suizo. Los datos individuales a nivel de animal se agregaron a nivel de rebaño. Dado que la recopilación y disponibilidad de datos eran las mejores para el ganado vacuno y porcino, la atención se centró en estas dos especies de ganado. Presentamos modelos de aprendizaje automático que pueden utilizarse como herramienta para planificar y optimizar las inspecciones de bienestar en las explotaciones basadas en el riesgo, proponiendo una lista consolidada de explotaciones prioritarias a visitar. Los resultados de inspecciones previas de bienestar en las granjas se utilizaron para calibrar un índice de bienestar binario, que es el objetivo de la predicción. El índice de riesgo se basa en información indirecta, como la participación en programas de bienestar animal con alojamiento estructurado y acceso al aire libre, el tipo y tamaño del rebaño o los datos de movimiento de los animales. Dado que la transparencia del modelo es fundamental tanto para la aceptación pública de un índice basado en datos como para la planificación del control de las explotaciones, se investigó en profundidad el modelo de bosque aleatorio, para el que se puede ilustrar el proceso de decisión. Utilizando datos históricos de inspección con una baja prevalencia general de violaciones de aproximadamente 4% para ambas especies, el índice desarrollado pudo predecir violaciones con una sensibilidad de 81.2 y 79.5% para granjas de ganado vacuno y porcino, respectivamente. El estudio ha demostrado que la combinación de fuentes de datos múltiples y heterogéneas mejora la calidad de los modelos. Además, los métodos de preservación de la privacidad se aplican a un entorno de investigación para explorar los datos disponibles antes de restringir el espacio de características a los más relevantes. Este estudio demuestra que el seguimiento basado en datos de las poblaciones de ganado ya es posible con los conjuntos de datos existentes y los modelos desarrollados pueden ser una herramienta útil para planificar y llevar a cabo inspecciones de bienestar animal basadas en el riesgo.
1 Introducción
La salud y el bienestar de los animales es un tema de importancia cada vez mayor. En este contexto, se inició en Suiza el proyecto Smart Animal Health (SAH), con el objetivo de desarrollar métodos basados en datos para evaluar la salud y el bienestar animal de diferentes especies ganaderas (1). La revisión de la literatura sobre los indicadores basados en datos y animales reveló grandes diferencias entre las especies animales, en lo que respecta a la disponibilidad de datos y la fiabilidad de los indicadores (2-7). Aunque se han obtenido altas correlaciones con la salud y el bienestar de los animales para algunos indicadores, se concluyó que actualmente se requiere una combinación de indicadores basados en datos y evaluaciones en las explotaciones para obtener una estimación completa del estado de salud y bienestar en las explotaciones (1). La revisión de las tecnologías disponibles de ganadería de precisión (PLF), que pueden proporcionar una alternativa objetiva y que ahorra tiempo a la recopilación manual de indicadores, también identificó diferencias sustanciales entre las categorías de animales y una gran discrepancia entre los sistemas PLF validados científicamente y los disponibles comercialmente (8-10). A diferencia de los indicadores «clásicos» y establecidos basados en animales descritos en las revisiones anteriores, que luego se compilan en protocolos para una evaluación exhaustiva del estado de salud, la parte del proyecto descrita en el estudio se centró en la integración de múltiples fuentes de datos para descubrir y estudiar correlaciones e indicadores previamente no reconocidos que pueden utilizarse como sustitutos.
Los datos de los animales se almacenan en varias bases de datos que reflejan el complejo panorama ganadero. El estudio de estas bases de datos y la obtención de información procesable pueden contribuir a mejorar la salud y el bienestar de los animales (11, 12). Los análisis basados en datos también pueden respaldar la vigilancia basada en el riesgo (13, 14). Durante décadas, la recopilación de datos sobre el sector ganadero en Suiza y Liechtenstein se ha ampliado constantemente (en lo sucesivo, el término Suiza debe interpretarse incluyendo el Principado de Liechtenstein debido a las políticas agrícolas comunes de los dos países). La recopilación de datos abarca múltiples aspectos de la política agrícola general y de las cuestiones veterinarias públicas (15). Los datos se utilizan para garantizar la trazabilidad (16), la seguridad y la calidad de los productos animales (17), vigilar y controlar la salud y el bienestar de los animales a nivel individual y poblacional (18) y asignar subvenciones directas a los ganaderos (19).
El análisis de las bases de datos de animales revela correlaciones entre los valores indirectos y los indicadores (20) o allana el camino para el desarrollo de gemelos digitales de granja (es decir, una simulación digital de la granja), que monitorearían o predecirían continuamente las métricas (21, 22). Por otra parte, los métodos comunes para la evaluación del bienestar animal se basan en datos registrados directamente en la explotación, como el protocolo de calidad® del bienestar (23). Sin embargo, existe una tendencia hacia un mayor uso de datos que se capturan de forma rutinaria y amplia, o hacia el uso de los llamados indicadores iceberg que reducen el número de parámetros y recursos necesarios (24-26). Otros métodos basados en datos han predicho con éxito el riesgo de enfermedad en el ganado lechero y han revelado relaciones previamente desconocidas entre los datos indirectos y la salud y/o el bienestar animal (27-29). En la actualidad, las estadísticas descriptivas que muestran la evolución de las poblaciones animales están a disposición del público (30), y hay muchas más estadísticas descriptivas que se pueden extraer. Se pueden agregar conjuntos de datos de terceros no centrados en animales para brindar más información, como la geografía (29), la duración del transporte o los datos climáticos.
En este estudio, nos centramos principalmente en datos específicos de la ganadería. Sobre la base de datos indirectos, construimos una herramienta de toma de decisiones de prueba de concepto para evaluar el bienestar animal en relación con la legislación suiza a nivel de granja para las explotaciones de ganado vacuno y porcino. El índice de riesgo modelizó los resultados de las inspecciones de bienestar animal de granja que se realizaban periódicamente utilizando clasificadores supervisados mediante la interconexión y la explotación de múltiples bases de datos. A diferencia del aprendizaje no supervisado, en el aprendizaje supervisado, un algoritmo debe entrenarse con datos etiquetados que se dividen en clases, y los datos no etiquetados se asignan a estas clases existentes. El índice de riesgo no pretende sustituir a los controles in situ, sino que se limita a proponer una lista de explotaciones que hay que vigilar y visitar con prioridad.
2 Materiales y métodos
En la Figura 1 se muestra el proceso de desarrollo del índice de riesgo y las fuentes de datos involucradas. Los datos de cuatro bases de datos individuales estaban interconectados: Acontrol, AGIS, AMD y ALIS. Los datos de inspecciones previas de bienestar en las granjas de Acontrol se utilizaron como etiquetas para calibrar un índice de bienestar binario (en riesgo/no en riesgo). Las características utilizadas para la predicción (es decir, variables proxy) se extrajeron de las otras tres bases de datos AGIS, AMD y ALIS. Se aplicaron y compararon cuatro algoritmos diferentes de aprendizaje automático. A continuación, se explican en detalle los pasos individuales y las bases de datos: (i) fuentes de datos, (ii) etiquetas y características, y (iii) algoritmos de clasificación.
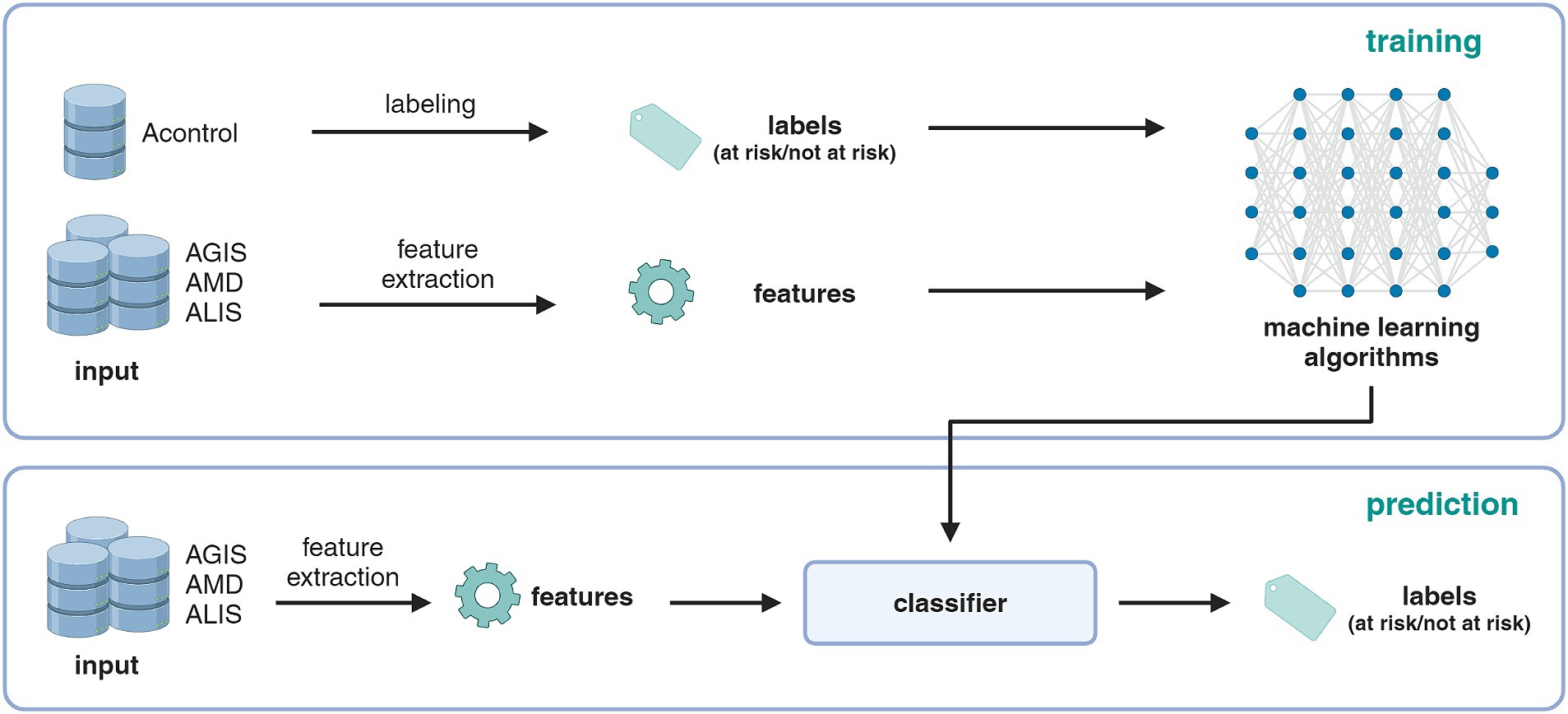
2.1 Fuentes de datos
Los datos ganaderos se almacenan en varias bases de datos que, por lo general, no están interconectadas, pero comparten identificadores únicos comunes para animales y granjas. Algunos de los registros se almacenan en bases de datos públicas, donde el contenido y el acceso están regulados por el derecho público, y algunos registros se almacenan en infraestructuras privadas (31). Estas bases de datos pueden registrar información con diferente granularidad. No restringimos las fuentes de datos anteriores en función de sus objetivos o uso. Sin embargo, seleccionamos solo fuentes de datos, donde los datos se recopilan de forma rutinaria de todas las explotaciones ganaderas, para lograr una calidad, cobertura (es decir, la fracción de granjas que informan para un parámetro determinado) y disponibilidad (es decir, accesibilidad). Concedimos un acceso seudónimo a las bases de datos que se describen a continuación. Sin embargo, por razones de privacidad y propiedad de los datos, no tuvimos acceso a todos los parámetros. A continuación, se describen brevemente las fuentes de datos utilizadas.
2.1.1 Sistema de datos de control (Acontrol)
La base de datos Acontrol contiene los resultados de las inspecciones obligatorias de bienestar animal en la granja, entre otros controles normalizados en el ámbito de la producción primaria (por ejemplo, higiene de la leche y documentación del uso y almacenamiento de medicamentos veterinarios). Estos datos sirvieron de base para el procedimiento de etiquetado (véase la sección 2.2.1), es decir, este es el estado que debe predecir el algoritmo de clasificación. Cada granja debe ser visitada e inspeccionada al menos cada 4 años (31). Se registra si una granja tuvo alguna violación en los distintos puntos de control. Los puntos de control individuales se agrupan en categorías. En la Tabla 1 se muestra una descripción general de estas categorías de control. En el caso de las explotaciones ganaderas, la inspección del bienestar en la explotación consta de 18 categorías de control, como las dimensiones mínimas y los requisitos de alojamiento, la calidad de la luz y del aire, el suministro de agua y las lesiones y el cuidado de los animales, mientras que la última categoría de control incluye los subpuntos de control de lesiones, cojera, condición corporal o animales sucios. El protocolo de inspección detallado puede obtenerse en la Oficina Federal de Seguridad Alimentaria y Veterinaria (FSVO) (32). En el caso de los cerdos, la inspección del bienestar consta de 15 categorías de control, que es similar a las del ganado vacuno (33). En la FSVO (34) se dispone de información y directrices adicionales sobre las inspecciones en las explotaciones. De esta manera, el estado de bienestar se definió como el cumplimiento/violación de los puntos de control de acuerdo con la normativa correspondiente. La base de datos Acontrol es administrada por la FSVO y la Oficina Federal de Agricultura (FOAG).

2.1.2 Sistema de Información sobre Política Agropecuaria (SIAG)
La base de datos AGIS (DE: Agrarpolitisches Informationssystem) de FOAG es una herramienta central para administrar las subvenciones públicas directas a los agricultores en Suiza y tiene una alta cobertura y calidad de datos. También sirve como centro para el uso coordinado y armonizado de los datos administrativos en las explotaciones agrícolas, principalmente a nivel federal (31). El sistema centraliza los registros de las explotaciones, como los datos estructurales (por ejemplo, el tipo de explotación y el sistema de producción, la superficie y el uso de la tierra, el tipo de especies ganaderas mantenidas o el número de cabezas por especie y categoría) y los programas de subvenciones directas. Estos programas incluyen dos programas etológicos/de bienestar animal financiados por el gobierno federal: «sistemas de alojamiento particularmente amigables con los animales» (BTS; DE: Besonders tierfreundliche Stallhaltungssysteme) y «acceso regular al exterior» (RAUS; DE: Regelmässiger Auslauf im Freien). Los programas BTS y RAUS demostraron ser de particular importancia en este estudio. Los programas etológicos BTS/RAUS especifican normas más estrictas en materia de bienestar animal en comparación con las establecidas en la legislación básica en materia de bienestar animal. El programa BTS exige que los animales se mantengan en alojamientos más grandes y estructurados, mientras que el programa RAUS exige que los animales tengan acceso a zonas exteriores con más frecuencia (35). Además, la concesión de pagos directos a los agricultores por defecto exige que el beneficiario cumpla los requisitos del certificado de rendimiento ecológico (OLN; DE: Ökologischer Leistungsnachweis) en toda la granja (36). Los requisitos de la OLN tienen por objeto, por ejemplo, aumentar la biodiversidad, limitar la contaminación atmosférica y equilibrar los flujos de nutrientes y fertilizantes, la rotación de cultivos y la protección del suelo. La participación en programas opcionales de la OLN también se registra en el AGIS.
2.1.3 Base de datos de movimiento animal (AMD)
El AMD (DE: Tierverkehrsdatenbank TVD) centraliza los datos sobre las siguientes especies: bovinos, caprinos, ovinos, porcinos, équidos, aves de corral, camélidos y animales de caza. Tiene el mandato legal de proporcionar datos de trazabilidad para animales individuales (en el caso de rumiantes y équidos) o grupos de animales (cerdos y aves de corral). Para todas las demás especies, solo se conoce la unidad ganadera. En el caso de las especies con registros individuales de animales, puede extraerse el total de las estancias y la información sobre el cuidador o el propietario, desde la notificación de nacimiento o importación hasta la notificación final de sacrificio o exportación. El AMD es desarrollado, mantenido y operado por Identitas AG bajo la dirección de FOAG y FSVO. No todas las especies están cubiertas con el mismo nivel de detalle o precisión. Los datos disponibles incluyen la identidad del animal, sus padres, una serie de fenotipos y eventos importantes (por ejemplo, nacimiento, salida y llegada a una explotación, y sacrificio). Las aves de corral, los pequeños rumiantes y los équidos no se consideraron en este estudio. Se utilizó como parámetro de entrada la presencia de estos animales en una granja. Las notificaciones de grupo describen la naturaleza del evento (llegada a una nueva granja o a una instalación de procesamiento) y el número de animales en el grupo. Se registra más información en la DMAE, como el estado de la enfermedad o información sobre la granja (por ejemplo, ubicación geográfica). AMD tiene una excelente cobertura. Un comentario sobre la calidad general de los datos es difícil porque varía para cada atributo. Oscila entre muy bueno para los datos básicos y las notificaciones comunes y la media para la localización geográfica precisa de la explotación y malo para los atributos opcionales adicionales, que también tienen una cobertura deficiente, como las razones para el sacrificio de animales.
2.1.4 Sistema de información de laboratorio (aRes, antes ALIS)
Este sistema FSVO centraliza los datos de laboratorio de los laboratorios autorizados del servicio veterinario público. Los datos incluyen los resultados de los diagnósticos de las enfermedades animales de declaración obligatoria de conformidad con la ordenanza suiza sobre enfermedades animales (37), incluidas las zoonosis que se llevan a cabo en nombre de los servicios veterinarios federales y cantonales en el marco de programas de vigilancia y control de enfermedades o de reglamentos sobre movimientos de animales. Para este estudio, se incluyeron en los modelos datos sobre los exámenes obligatorios de aborto en el ganado (es decir, para la rinotraqueítis infecciosa bovina, la diarrea viral bovina, la brucelosis y la coxiellosis) (38).
2.1.5 Otras bases de datos
En este estudio, otras dos bases de datos fueron de gran interés: el sistema de información sobre antibióticos en medicina veterinaria (IS-ABV) y la base de datos de inspección de carne (FLEKO). Sin embargo, ambos se introdujeron solo durante el proyecto de investigación y, por lo tanto, no pudieron considerarse como fuentes de parámetros de entrada debido a la baja cobertura, la seguridad restrictiva de los datos y, hasta ahora, la insuficiente calidad de los datos.
2.1.6 Extracción de datos
El desarrollo del índice de riesgo se limitó a las granjas de ganado bovino y porcino por razones de cobertura y calidad de los datos. Los datos se anonimizaron antes del procesamiento de acuerdo con los acuerdos de procesamiento de datos con las autoridades competentes. Se acordó un procedimiento de seudonimización para satisfacer la necesidad de puntos de datos precisos e imparciales. El libro de códigos de identificación fue construido por la FSVO y se mantuvo confidencial. La FSVO también seudonimizó los datos de las fuentes de datos públicas de las oficinas federales y los datos eran anónimos para nosotros. La ventana temporal de los datos seleccionados en este estudio es desde enero de 2014 hasta finales de octubre de 2019, abarcando casi 6 años. Durante este período de tiempo, más de 48.700 explotaciones (incluidas las explotaciones de verano y otras explotaciones temporales) registraron activamente el ganado. Un total de 15.800 explotaciones ganaderas participaron en el comercio de cerdos durante los 6 años.
2.2 Etiquetas y características
Los datos se homogeneizaron, formatearon y normalizaron para ser utilizados como características (es decir, parámetros de entrada) o etiquetas (es decir, el objetivo de cada participación) para los algoritmos de aprendizaje automático. Algunos de los datos eran categóricos y otros numéricos. La mayoría eran series temporales con diferentes periodos de tiempo, que pueden presentar variaciones estacionales fuertes y complejas. En esta sección, describimos las principales técnicas de preprocesamiento. Hacemos hincapié en que nuestro objetivo era predecir el estado de bienestar animal a nivel de granja. La etiqueta «estado de bienestar», o índice de riesgo en lo sucesivo, debe reflejar los hallazgos de las inspecciones en la granja y basarse en datos indirectos que no se recopilaron durante esas visitas.
2.2.1 Preparación de la etiqueta
Sobre la base de los resultados históricos de las inspecciones en la granja registrados en la base de datos de Acontrol, se construyó una métrica escalar. De acuerdo con la Ley y las Ordenanzas Suizas sobre Bienestar Animal, el estado de bienestar se definió como el cumplimiento/violación de los puntos de control (39-41). Todos los puntos de control fueron tratados por igual, y los diversos subpuntos (p. ej., cojera, condición corporal) no se etiquetaron individualmente. Las visitas de control de seguimiento no se tuvieron en cuenta debido a violaciones anteriores. Se aplicó un esquema de ponderación para disminuir el peso de las inspecciones anunciadas (factor de 0,8) en comparación con las inspecciones no anunciadas (factor de 1). Además, si se realizaba más de una inspección durante el período de tiempo seleccionado, la importancia de las inspecciones más antiguas también se reducía mediante un esquema de ponderación exponencial. Por último, la etiqueta del índice de riesgo es un valor binario que depende de la fracción de inspecciones con infracciones registradas sobre el número total de controles (relevantes). Para que una participación se considere «en riesgo», este proxy debe ser mayor o igual a 0,5.
2.2.2 Extracción de características
Hay varios formatos diferentes para los datos de entrada. Las características se eligieron para que fueran escalares y la extracción de características se diseñó de manera que se redujera la dimensionalidad; Las series temporales se agregaron o clasificaron en categorías basadas en datos. La participación de una explotación en programas individuales, como «producción lechera basada en pastizales» o «áreas de promoción de la biodiversidad» (42), se agrupó por temas más amplios (por ejemplo, otras OLN). Los datos categóricos (por ejemplo, el cantón o el tipo de retención) se codificaron utilizando un esquema one-hot (es decir, una característica categórica que contiene K valores posibles, que se transforma en K características binarias). Las distribuciones se codificaron mediante estadística descriptiva simple.
En el caso del ganado vacuno, se prepararon descripciones de los rebaños por explotación, edad y sexo. Esto incluyó el recuento de cabezas, la edad media, el número de razas diferentes, la fracción del tipo de raza (lechera, de carne de vacuno o dual) y la fracción de nombres no técnicos dados al ganado. Las notificaciones al registro de AMD se contaron por tenencia y por tipo. La edad de los animales en el momento de la notificación y los retrasos en la notificación entre el evento y la notificación se describieron utilizando percentiles 5, 25, 50, 75 y 95. Además, se estimó la fracción de novillas y vacas para cada tipo de notificación. AGIS proporciona un recuento anual de cabezas por categoría de animales, que se incluyó para el análisis de las explotaciones de ganado vacuno y porcino. La evolución del número de cabezas de ganado por categoría depende del tipo de explotación y de las prácticas. Agregar esta información sin tener en cuenta la dinámica de los rebaños resultaría en una pérdida de información. Utilizando el algoritmo euclidiano de agrupamiento de k-medias (43), estas series temporales se transformaron en características categóricas.
En el caso de los cerdos, las notificaciones de transporte se extrajeron de la AMD. En cuanto al ganado, se extrajo el tipo de notificación y la descripción del retraso. El origen y el destino de los transportes se utilizaron para calcular las distancias y los tiempos de viaje (44). La duración del transporte medida se informará de forma rutinaria en el AMD. Sin embargo, actualmente, solo se notifica el origen y el destino.
Las características no categóricas se normalizaron. Los valores medios o percentiles de las series temporales se normalizaron por el total de las categorías correspondientes, es decir, cada categoría de ganado se normalizó por el número total de animales. En las bases de datos disponibles, algunos parámetros estaban muy incompletos, y algunos registros tenían una cobertura inferior al 50%. Los datos faltantes (por ejemplo, muchas explotaciones carecían de una entrada para las unidades de mano de obra estándar) se reemplazaron por un 0, lo que no pone el parámetro faltante en un enfoque excesivo durante el análisis. Hay algunas razones diferentes por las que faltan valores, como valores incorrectos ingresados manualmente; La retención de la propagación de datos de la recopilación a la base de datos final aún no se ha implementado completamente. Un valor faltante también puede ser informativo en este contexto. Por último, todas las entidades se sometieron a un escalado estándar, que impone una media cero y una varianza unitaria.
En las Tablas 2 y 3 se presenta una visión general de los temas y grupos de características. Además, en la sección de resultados se presenta una descripción más detallada de las características más importantes.
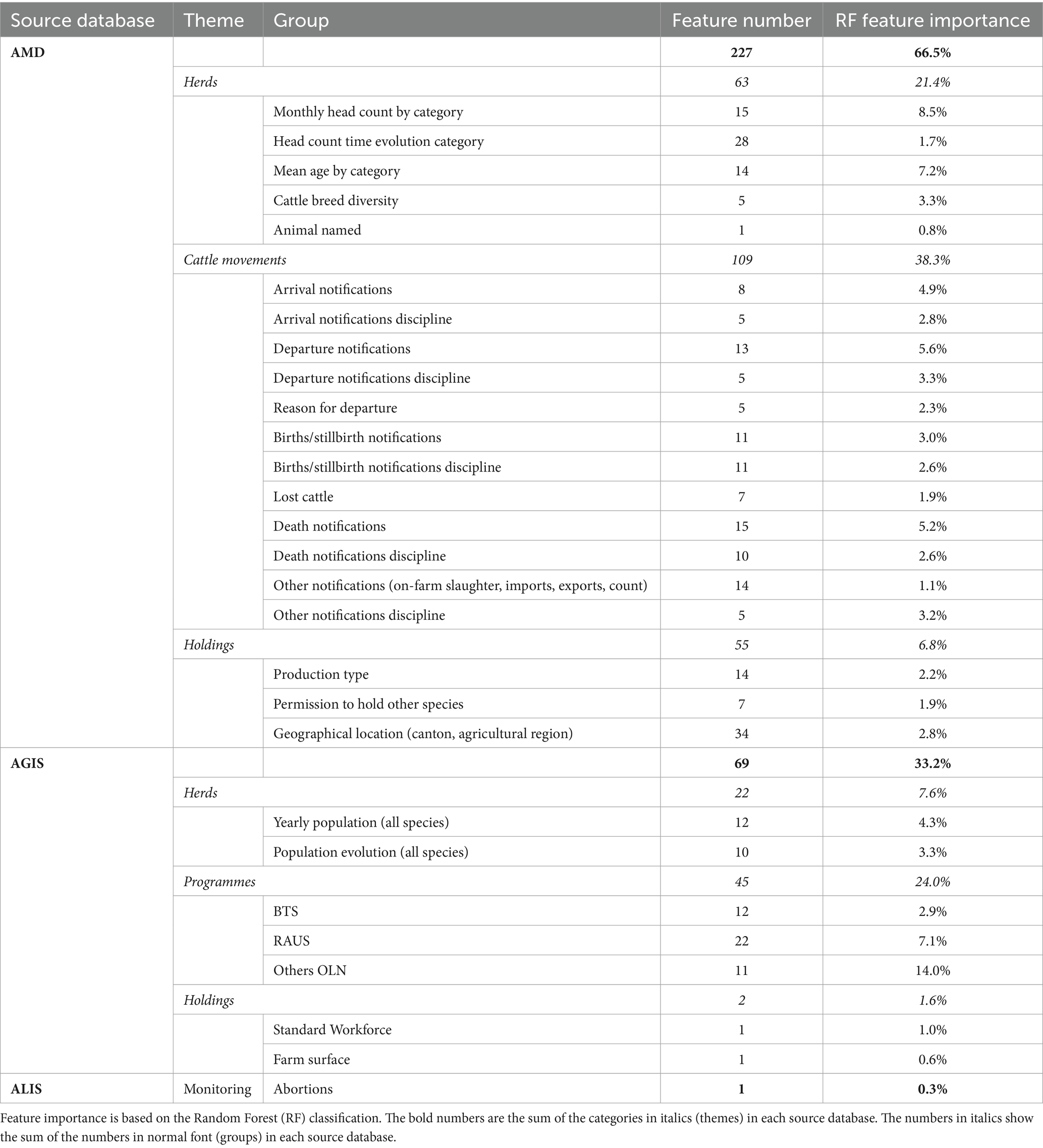
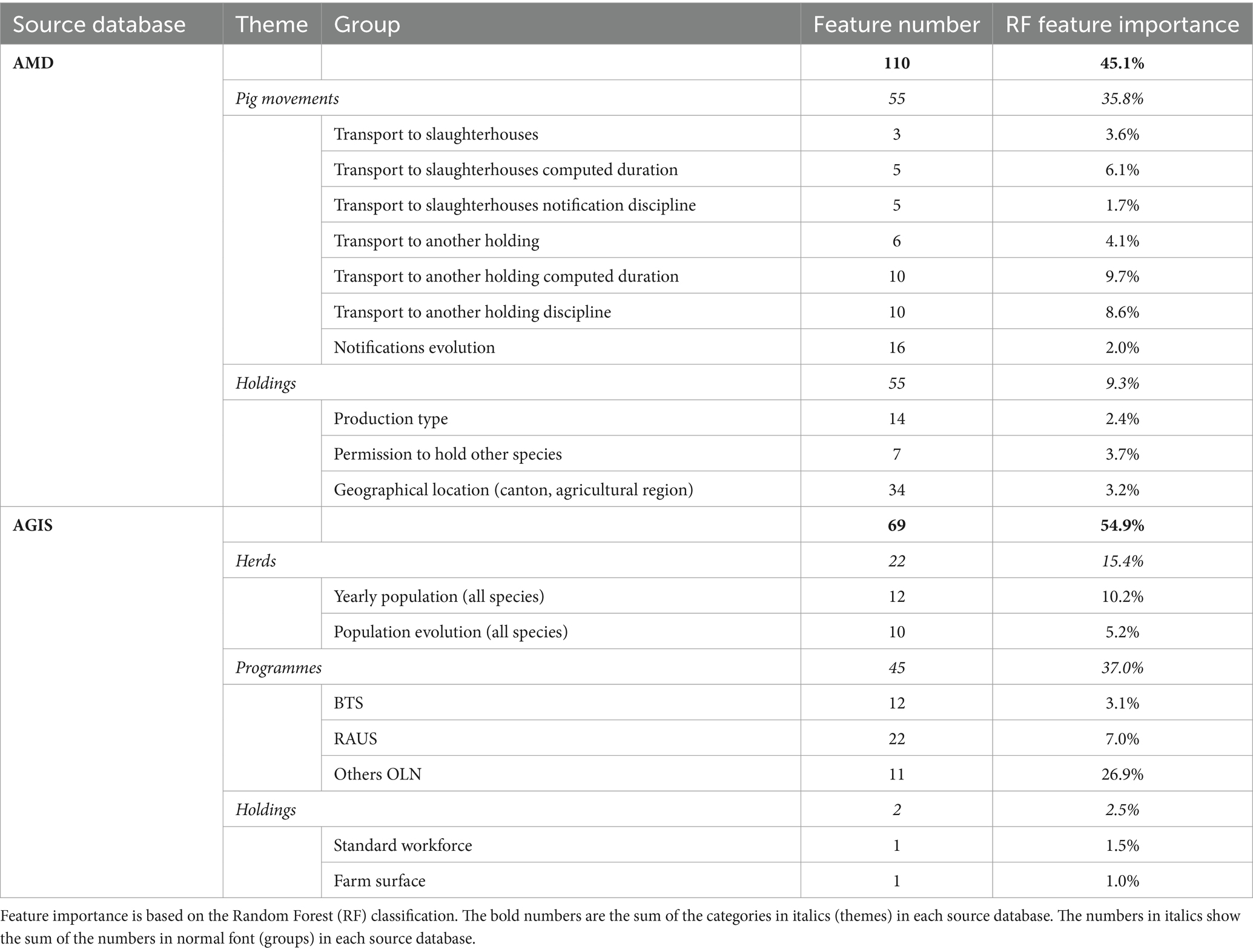
2.2.3 Descripción del conjunto de datos consolidado
Los conjuntos de datos consolidados que contienen las diferentes características se utilizaron como datos de entrada para los algoritmos de clasificación aplicados. En cuanto al ganado bovino, de las 36.904 explotaciones con al menos un registro en Acontrol, 1.437 (prevalencia de 3,89%) presentaron ≥50% de infracciones, por lo que se clasificaron en riesgo. Cada explotación fue descrita por 297 características. En el caso de los cerdos, de las 2.432 explotaciones con al menos un registro en Acontrol, 110 (prevalencia del 4,52%) mostraron un ≥50% de violaciones y se clasificaron como de riesgo. En el caso de las explotaciones porcinas, había 179 características. Por lo tanto, los conjuntos de datos estaban desequilibrados. Todos los algoritmos se entrenaron en conjuntos de entrenamiento equilibrados. Para incluir más variabilidad en el conjunto de entrenamiento, optamos por sobremuestrear la categoría en riesgo en un factor de seis.
2.3 Algoritmos de clasificación
El índice de riesgo, tal como se ha descrito anteriormente, es una cantidad booleana y, por lo tanto, el cálculo del índice es, por lo tanto, una tarea de clasificación de clases binarias. La implementación de la biblioteca Python scikit-learn (45) se utilizó para todos, pero se utilizaron las redes neuronales artificiales (ANN) para Keras (46).
Se utilizó el bosque aleatorio (RF) como referencia debido al bajo número de metaparámetros y a la interpretabilidad. Construimos un bosque de 500 árboles de decisión utilizando el criterio de entropía. Las RNA con la siguiente arquitectura utilizaron dos capas ocultas de 30 neuronas con activación de unidad lineal rectificada y una capa de clasificación con una función de activación sigmoide que produce un escalar. La red se entrenó con pérdida de entropía cruzada binaria y un término de regularización L1 utilizando el optimizador Adam. La elección de este método se justificó por el buen rendimiento y la flexibilidad. Sin embargo, las RNA son notoriamente difíciles de inspeccionar. Se probaron otros algoritmos, como máquinas de vectores de soporte (SVM, o SVC, con un kernel de función de base radial) y regresiones logísticas. Finalmente, se construyó un clasificador de compromiso que considera las respuestas de todos los modelos y pondera la puntuación de acuerdo con el rendimiento de cada algoritmo individual. Este procedimiento se conoce como sistema de votación de comité o comité, en resumen.
Para el entrenamiento, validación y prueba de los algoritmos, se utilizaron tres conjuntos independientes, que se dividieron en entrenamiento (70%), validación (10%) y prueba (20%). Entre cada experimento de clasificación, todos los conjuntos se seleccionaron aleatoriamente para garantizar que los clasificadores no se entrenaran en los mismos subconjuntos. Todos los métodos mencionados anteriormente (excepto ANN) tienen algunos umbrales de decisión incorporados, que generalmente se establecen en 0,5 de la puntuación de clasificación. Se pueden seleccionar diferentes heurísticas para optimizar el umbral de decisión. Experimentamos con tres métodos diferentes: (i) maximizando la puntuación F1, (ii) imponiendo una tasa de falsos positivos (FPR) del 20% y (iii) maximizando el valor «F1-score—0,1FPR». Seleccionamos el compromiso (opción iii) para mantener el FPR en un nivel relativamente bajo mientras apuntamos a los mejores rendimientos.
Debido a la naturaleza estocástica del entrenamiento y al número relativamente bajo de muestras de entrenamiento, la clasificación se repitió 1.000 veces. Esto resolvió las variaciones del entrenamiento en los rendimientos finales del clasificador y permitió evaluar la desviación estándar del entrenamiento.
3 Resultados
3.1 Índice de riesgo de las explotaciones ganaderas
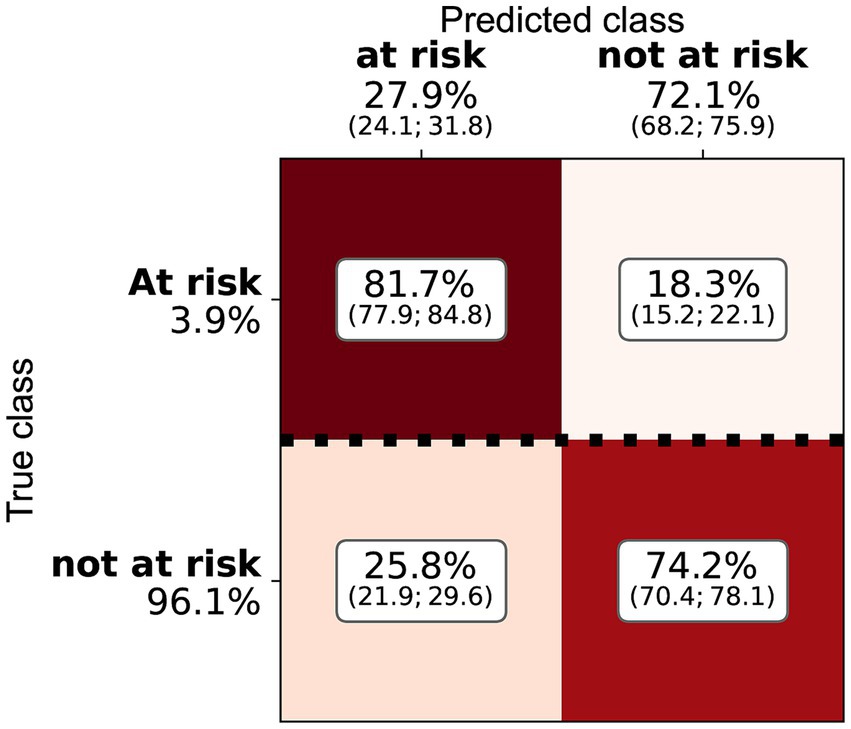
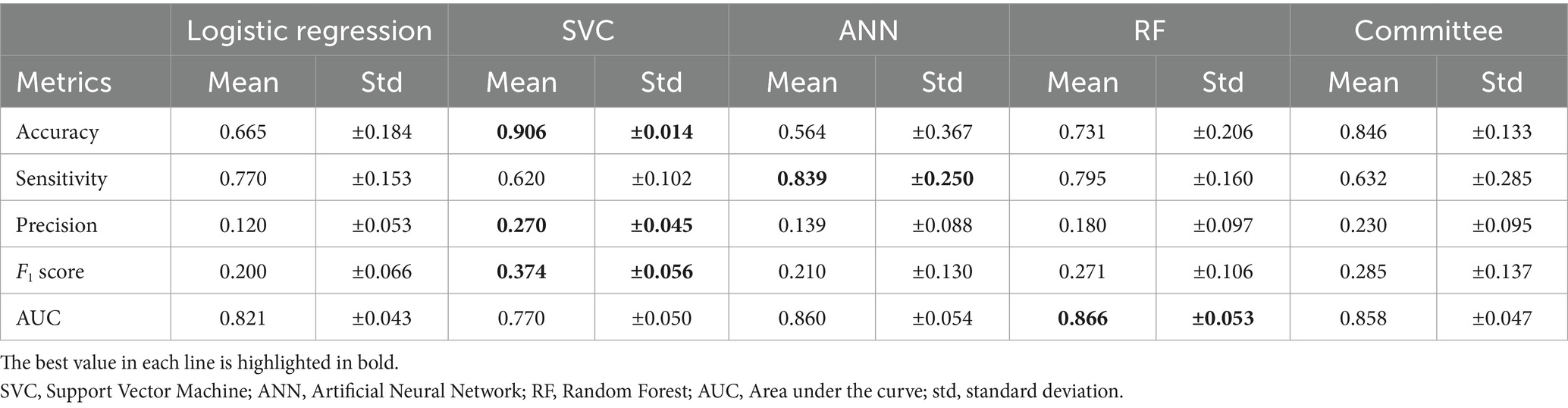
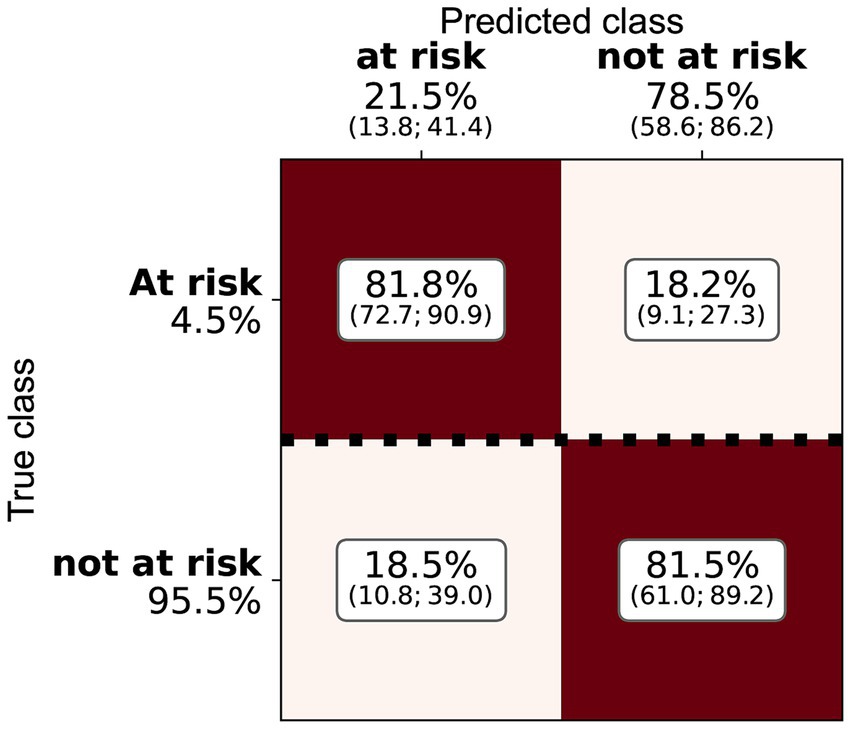
Tres de los algoritmos aplicados mostraron un rendimiento similar (ANN, RF y regresión logística; véase la Tabla 4 y la Figura 2). Se han explorado varias arquitecturas para ANN, la mayoría de las cuales exhiben un rendimiento muy similar. RF y ANN tendieron a mostrar un rendimiento ligeramente mejor debido a la menor variación de sus métricas. SVM mostró una precisión significativamente mayor, pero una sensibilidad mucho menor. La SVM podría considerarse un método más conservador. Dado que la sensibilidad era sustancialmente menor, muchas participaciones en riesgo no se clasificaron correctamente. La matriz de confusión para RF (Figura 3) muestra que la sensibilidad mediana fue del 81,7%. Los entrenamientos individuales alcanzaron entre el 78 y el 85% en los niveles del percentil 25 y 75. La RF alcanzó una precisión media del 11,5% y una exactitud del 74,1%.
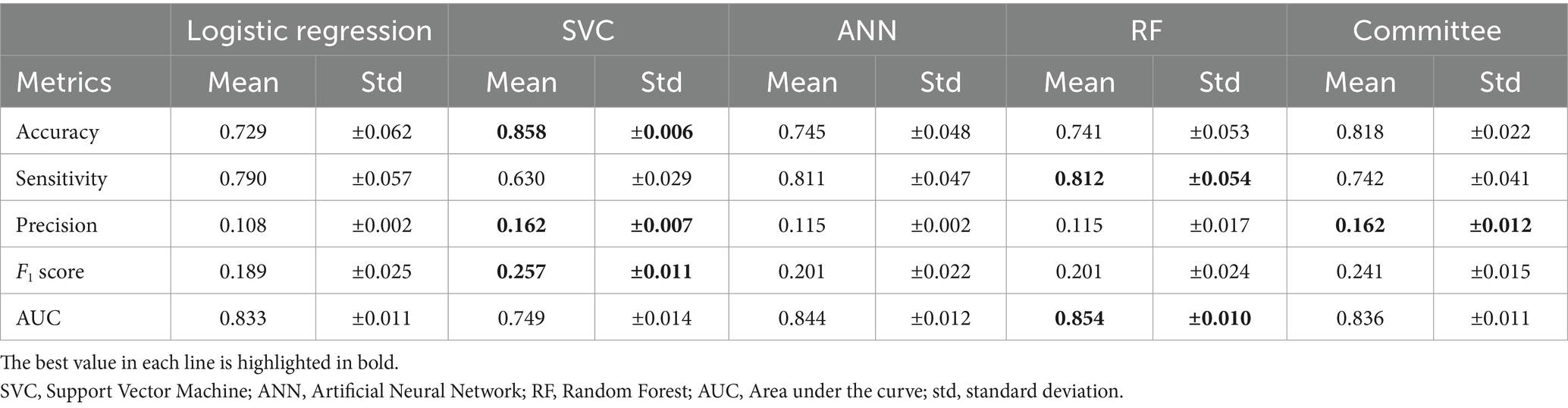
Tabla 4. Media y desviación estándar de las métricas de rendimiento de las explotaciones ganaderas.
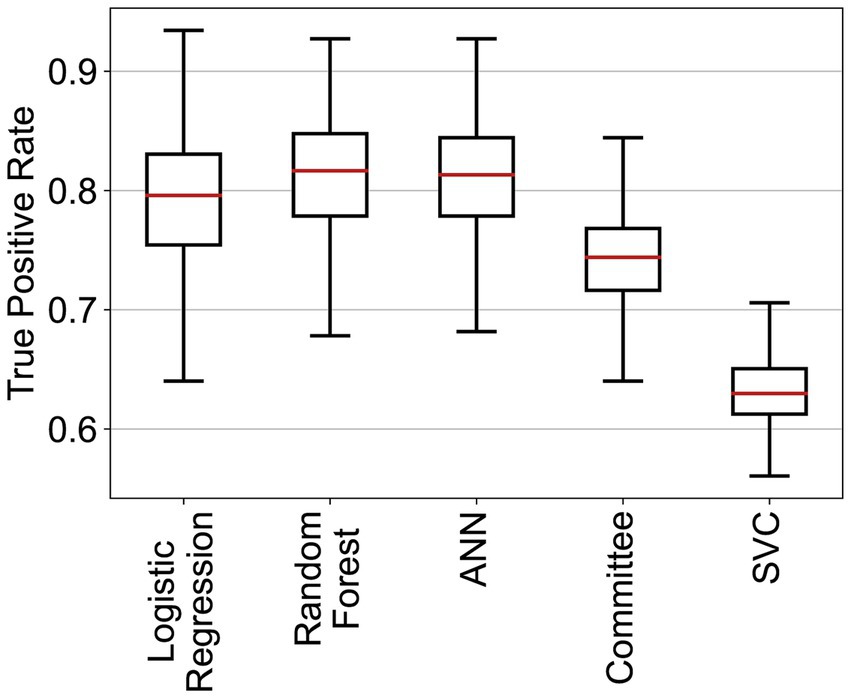
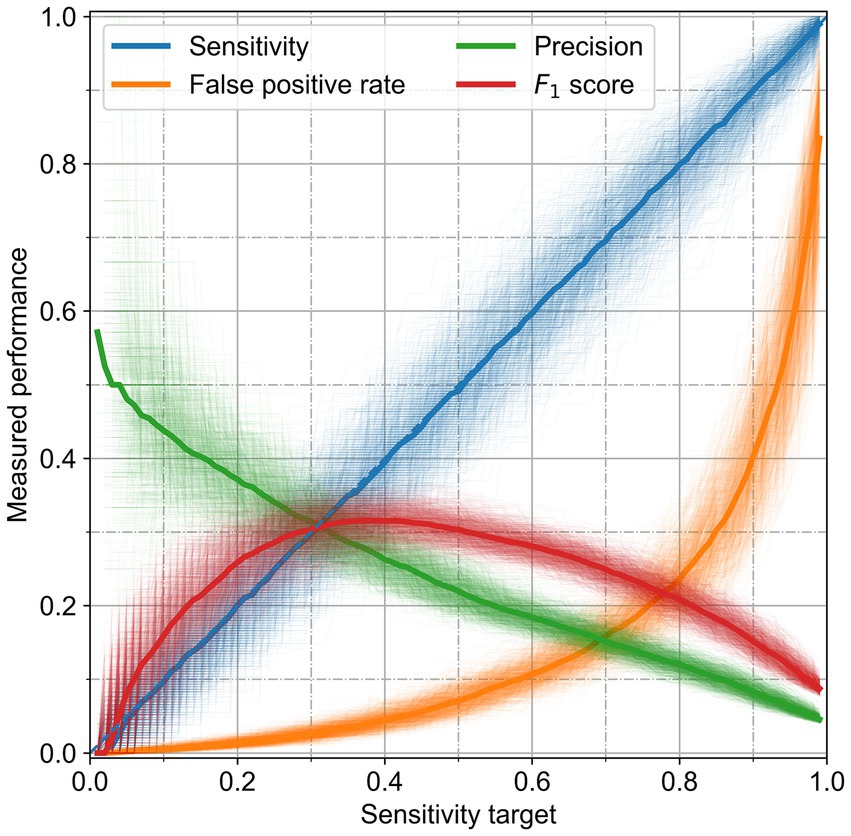
Elegimos establecer una heurística de compromiso entre precisión y sensibilidad. Esta heurística alcanzó el mejor rendimiento posible para todos los clasificadores. La Figura 4 muestra las diferentes métricas de rendimiento en función de la sensibilidad del objetivo para la RF. Los algoritmos podrían alcanzar el conjunto de rendimiento. En su punto máximo, la puntuación F1 puede alcanzar valores de hasta el 32%, con una precisión del 25%, pero una baja sensibilidad del 40%. Las carreras individuales mostraron una buena similitud con el rendimiento medio; las desviaciones estándar se presentan en la Tabla 4. La RF se comportó mejor que los otros algoritmos para cualquier sensibilidad elegida, ya que tiene una mayor precisión y una tasa de falsos positivos más baja.
3.2 Índice de riesgo de las explotaciones porcinas
La variabilidad de las métricas de rendimiento fue mayor para los cerdos que para el ganado bovino (Figura 5). Como se muestra en la Tabla 5, el SVC tuvo una puntuación de precisión media muy alta del 90,6%, pero la sensibilidad del 62,0% fue mucho menor que los otros métodos. La RF reveló, al igual que para el ganado, el mejor equilibrio entre la sensibilidad (79,5%) y la precisión (18,0%, Figura 6). La precisión de RF alcanzó el 73,1%. Así, los resultados para bovinos y porcinos fueron muy similares. La principal diferencia de rendimiento con los clasificadores para las explotaciones ganaderas fue la variabilidad de los métodos.

3.3 Importancia de las características
3.3.1 Ganado vacuno
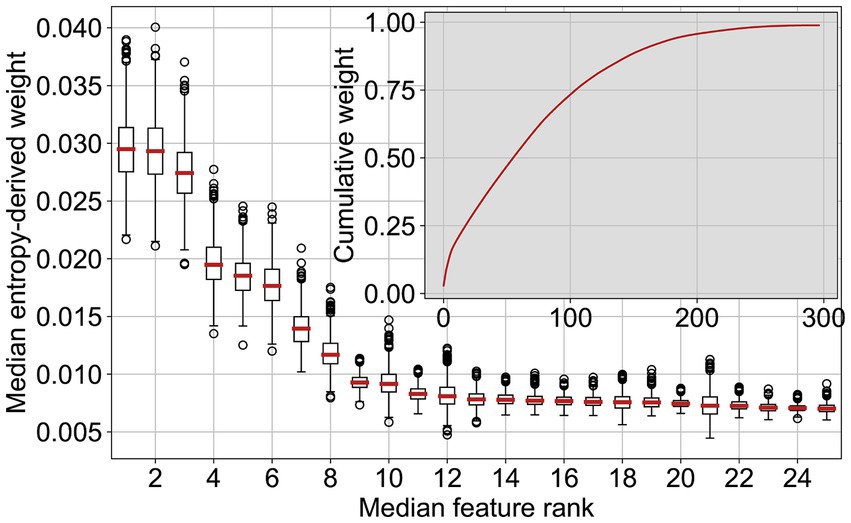
La lista de las características de RF más importantes para el ganado reveló que las 50 características principales representan casi el 50% del peso de decisión (Figura 7). Los diagramas de caja de la Figura 7 representan la variabilidad de ejecución a ejecución de la importancia de las características para las 25 características más importantes. Si bien hubo algunas variaciones, el orden de las características, o el orden de sus grupos agregados por tema, no cambió significativamente. En el Cuadro 2 se presenta la importancia de las características para todos los grupos de características del ganado. La participación en los programas del sistema de producción (por ejemplo, BTS, RAUS y OLN) se correlacionó considerablemente con un buen estado de salud y bienestar, es decir, el cumplimiento de los puntos de control en las inspecciones de bienestar en las explotaciones. Las características asociadas a estos programas (45 características) representaron el 24% de la decisión. A continuación, las características se resumen en grupos y los valores se mencionan entre paréntesis que representan la importancia del grupo. El orden en el que se citan las características sigue la importancia de cada característica en el árbol de decisión. Después de los programas del sistema de producción, algunas características estructurales fueron las siguientes en orden de importancia. La fuerza de trabajo estándar fue una de las características más importantes (1% de la decisión, una característica) a pesar de estar incompleta. El hecho de que la granja estuviera registrada como una granja de cría durante todo el año (DE: Ganzjahresbetrieb) también fue una señal binaria importante (1%, una característica). La primera característica está directamente relacionada con los animales, en lo que respecta al recuento de cabezas y la evolución del tiempo por categoría (10,2%, 43 características), la edad por categoría (7,2%, 14 características), las notificaciones de salida y la edad a la salida (5,6%, 13 características), la disciplina de las notificaciones de salida (3,3%, 5 características) y sus razones (2,3%, cinco características). Algunas de estas características importantes también se refieren a la diversidad de razas en el rebaño (3,3%, cinco características). La proporción de animales con nombres no técnicos también ocupó un lugar alto (0,8%, una característica). La fracción de animales que mueren es la primera característica, que está directamente relacionada con la salud y el bienestar (5,2%, 15 características), seguida de la fracción de ganado perdido, es decir, el ganado que salió de una explotación (1,9%, siete características) pero, según los registros de la AMD, nunca llegó a otra explotación o matadero. Las características relacionadas con los mortinatos se clasificaron relativamente bajo y podrían ser ligeramente menos significativas que los animales perdidos (3,0%, 11 características). La superficie de la explotación (DE: landwirtschaftliche Nutzfläche) fue importante (0,6%, una característica).
3.3.2 Cerdos
En el Cuadro 3 se presenta una visión general de la importancia de las características para todos los grupos de características de los cerdos. El análisis de las características de los cerdos fue similar al del ganado vacuno: unas pocas características importantes y una larga cola de características mucho menos significativas. Las características más importantes se agrupan en lo que se puede llamar programas ecológicos y de bienestar animal (37%, 45 características), que comprenden tres grupos, a saber, BTS, RAUS y «otros OLN». A continuación, la mano de obra estándar (1,5%, una característica) y la superficie de la granja (1%, una característica) desempeñaron un papel clave. Las especies animales distintas de los cerdos (8,4%, 10 características) que se mantienen en la explotación se encuentran entre las características más importantes, en particular la presencia de ganado vacuno. Además, las notificaciones de transporte, en particular la fracción de transportes a mataderos (3,6%, tres características), eran relevantes. Lo mismo ocurre con la duración calculada del transporte a los mataderos o a otras explotaciones (15,8 %, 15 características). También fue importante el flujo de cerdos que llegan o salen de una explotación (4,1%, seis características). Para todas las notificaciones de transporte, las duraciones del transporte fueron más relevantes que la disciplina de notificación (10,3%, 15 características).
3.4 Análisis de sensibilidad
Para probar la sensibilidad de los rendimientos al número de características, seleccionamos solo las 100 más importantes en el modelo de ganado de acuerdo con la lista del párrafo anterior, que representan más del 75% de la decisión, y retomamos la clasificación. Las métricas de rendimiento resultantes fueron estadísticamente coherentes con las ejecuciones de todas las características. Además, para revertir la fracción real de violaciones a la salud y el bienestar (en lugar de clasificar las explotaciones entre en riesgo y no en riesgo), la extensión experimental del método no mostró ninguna mejora con respecto a los resultados presentados en las secciones anteriores. Los análisis adicionales llevados a cabo para la comparación de la importancia de las características de la regresión logística revelaron que el orden de las características es más o menos similar al de la RF para los cerdos. Esto era de esperar debido a las actuaciones muy similares. En el caso de los experimentos con ganado vacuno, observamos que el tipo de notificaciones, en particular las relacionadas con la mortalidad, y el tipo de producción fueron las características más importantes para la regresión logística.
4 Discusión
Sobre la base de los análisis, se determinó que RF son los algoritmos más adecuados, ya que las clasificaciones pueden explicarse y la pérdida de rendimiento de las métricas individuales es menor en comparación con otros algoritmos probados. Además, la Federación de Frecuencia ha mostrado una alta sensibilidad hacia las violaciones de la asistencia social, lo que permite la detección de un alto número de casos verdaderos positivos, lo cual es importante en el contexto de los objetivos más amplios de este estudio. Sin embargo, debido a la baja prevalencia general de las violaciones para ambas especies animales (aproximadamente el 4 %), una tasa de falsos positivos pequeña pero distinta de cero conduce a múltiples resultados de falsos positivos. Como resultado, la precisión general es relativamente baja, oscilando entre el 11 y el 15% para las explotaciones ganaderas y entre el 18 y el 20% para las granjas porcinas (Tablas 4 y 5). No obstante, la precisión puede incrementarse en un factor de 3 a 5 en comparación con una selección aleatoria de explotaciones para las inspecciones de bienestar animal en la granja. Dado que también existen clasificaciones de falsos negativos, los resultados de este estudio deben considerarse como una lista de prioridades para la planificación y realización de inspecciones en las explotaciones, en lugar de una lista concluyente de explotaciones con problemas de bienestar animal.
4.1 Análisis de características
La importancia de que las explotaciones participen en programas etológicos y/o ecológicos sugiere que estos programas tienden a alcanzar sus objetivos. Sin embargo, son una fuente potencial de sesgo si las explotaciones participan en estos programas pero no cumplen plenamente con las normas de producción correspondientes. La ubicación geográfica también influyó en la clasificación. Es posible que a nivel local haya más granjas en riesgo de violaciones del bienestar social por diferentes razones, como los tipos de producción, el énfasis local en los controles o incluso las tradiciones. Esta hipótesis implicaría que el sesgo local de los controladores no es compensado por el clasificador. Sin embargo, nuestros conocimientos actuales no sugieren que esta explicación sea cierta y, por el contrario, refuerza la conclusión de que, efectivamente, hay más explotaciones en riesgo en determinadas regiones. A pesar de que la diversidad de las especies animales que se poseían era importante para los cerdos, existe una correlación, al menos en el caso de los cerdos, entre el bienestar y el número de especies animales criadas en una unidad ganadera en particular. En el caso de los cerdos, las características de la duración del transporte calculada eran más pertinentes que la disciplina de notificación.
En ambos casos, algunas de las características apenas tienen impacto. Esto puede deberse a que no son una buena información proxy y, por lo tanto, no son relevantes porque la función está mal diseñada y no contiene la información relevante. Una característica que sería demasiado ruidosa también se clasificaría como poco informativa, incluso si fuera relevante a priori. Distinguir la causa de la falta de importancia no es trivial. El hecho de que el número de características se pueda reducir al 75% de la decisión sin cambiar los resultados principales, y la afirmación anterior parecen sugerir que hay un margen de mejora en la elección y el diseño de las características. También sería beneficioso utilizar nuevas bases de datos más estrechamente relacionadas con la salud y el bienestar. Sin embargo, estas bases de datos aún no estaban listas para su implementación o la calidad de los datos era insuficiente cuando se realizó el estudio.
Inicialmente, se esperaba que la dinámica de la población animal a lo largo del tiempo jugara un papel. Para ambas especies animales, ninguna de estas características se encuentra entre las 50 más importantes. El agrupamiento de la dinámica poblacional puede ser demasiado complejo y ruidoso para recuperar información significativa o ya está codificado en otros parámetros, como el tipo de explotación.
Un pequeño número de participaciones se clasifica sistemáticamente de forma errónea. Estas explotaciones en su mayoría no participaron en programas etológicos, es decir, algunas de las participaciones que no se suscribieron a BTS/RAUS se clasificaron como en riesgo de forma coherente a lo largo de las diferentes sesiones de formación, aunque no estuvieran en riesgo. Este efecto es especialmente fuerte en el caso de las explotaciones con vacas lecheras que no participan en programas de servicios ecológicos. Este sesgo podría deberse al pequeño tamaño del conjunto de entrenamiento (y, por lo tanto, más datos podrían compensar el efecto), pero también podría deberse a una sensibilidad excesivamente alta de la participación en los programas. Esto podría ser una manifestación de la limitación de los datos indirectos y debería investigarse en trabajos futuros. Los hábitos locales o tradicionales, o las condenas de los agricultores, dadas las violaciones del bienestar animal, tienen una gran influencia en los resultados. Los ganaderos que participaron en programas ampliados de servicios ecológicos también pueden ser más sensibles a la salud y el bienestar de su rebaño, o invierten más tiempo en la observación y el cuidado, y esto no se refleja en la información indirecta de que disponen.
4.2 Análisis de clasificación
Las explotaciones ganaderas se clasificaron con la misma precisión que las explotaciones ganaderas. Debido a la menor cobertura de datos en comparación con el ganado, esto fue algo inesperado. Sin embargo, el hallazgo podría ser el resultado del menor tamaño de la muestra; Las granjas porcinas son bastante homogéneas en comparación con los sistemas de producción ganadera mucho más diversos.
Cuando la importancia de la característica se combina con la predicción individual, las características relevantes se pueden calcular para cada explotación. Las características se pueden clasificar de acuerdo con su contribución a la decisión final de las explotaciones individuales y explicar la clasificación de estas explotaciones individuales.
Para ambas especies, el espacio de características es dimensionalmente grande. Dar un rango unidimensional de valor para una característica arbitraria que implica una clasificación en riesgo es excesivamente difícil. No tiene sentido debido a la marginación sobre las otras características. Por ejemplo, una tasa de mortalidad más baja siempre es mejor; Sin embargo, algunas circunstancias podrían explicar ciertos niveles que podrían considerarse normales. No cabe esperar la misma tasa de mortalidad en una explotación con terneros jóvenes o novillas. Las herramientas de inspección permiten considerar estos efectos si fueron detectados por el clasificador durante la fase de entrenamiento. El análisis de la(s) clasificación(es) no debe llevar a conclusiones ingenuas o demasiado simplificadas. Puede haber fuertes correlaciones, pero no implican causalidad. Una predicción de «en riesgo» no implica que realmente haya un problema, sino simplemente que la probabilidad de violaciones de la asistencia social es mayor. La función de inspección también proporciona posibles áreas de mejora para las explotaciones, que pueden tener un impacto positivo en la salud y el bienestar de los animales, sobre la base de datos indirectos. Tales esquemas serían difíciles de manipular o falsificar. Es posible que forzar algunas características no tenga el impacto deseado. La mayoría de las funciones se basan en las notificaciones, que son difíciles de falsificar. Otras características son redundantes y, por lo tanto, están protegidas contra la manipulación.
5 Conclusión
Los resultados del presente estudio demuestran que, mediante la combinación de datos históricos de inspección con otras bases de datos ganaderas existentes y la aplicación de algoritmos de aprendizaje automático, es posible identificar las explotaciones con un mayor riesgo de violaciones del bienestar y recomendar estas granjas para una inspección del bienestar animal en la granja. Los modelos lograron sensibilidades superiores al 80% y una precisión del 12-18%. Esto significa que el índice descubre correctamente la mayoría de las participaciones, que tienen un historial de violaciones de la salud y el bienestar. Los grupos de características más importantes para las dos especies estudiadas fueron la participación en programas etológicos y ecológicos y las características de la DMAE, como las notificaciones de salida, el historial de notificaciones y el retraso, y, en el caso de los cerdos, la duración calculada del transporte. Estos hallazgos sugieren que aspectos supuestamente triviales, como la notificación, la disciplina o el nombramiento de los animales, tienen efectos positivos en procesos complejos como la salud y el bienestar. El trabajo futuro debería centrarse en la integración de nuevas fuentes de datos y en la mejora del diseño de las características para mejorar aún más la sensibilidad y la precisión de los modelos. Dado que varios puntos de subcontrol del protocolo de inspección en la explotación (por ejemplo, la cojera y la condición corporal) no estaban etiquetados individualmente, el índice de riesgo no puede aplicarse para indicar la probabilidad de violaciones de puntos de control específicos, sino solo combinarlos de manera no específica en todos ellos. Sin embargo, los modelos actuales ya se pueden utilizar para crear listas de prioridades que se pueden utilizar para planificar y realizar inspecciones basadas en el riesgo de las explotaciones bovinas y porcinas para determinar el verdadero estado de bienestar animal.
Declaración de disponibilidad de datos
Los datos analizados en este estudio están sujetos a las siguientes licencias/restricciones: los datos brutos que respaldan las conclusiones de este artículo son confidenciales y serán puestos a disposición de forma anónima por los autores previa solicitud. El acceso a los datos públicos está regulado por el derecho público. Las solicitudes para acceder a estos conjuntos de datos deben dirigirse a la Oficina Federal de Seguridad Alimentaria y Veterinaria (FSVO), así como a la Oficina Federal de Agricultura (FOAG).
Contribuciones de los autores
BT: Conceptualización, Curación de datos, Investigación, Metodología, Redacción – borrador original, Redacción – revisión y edición, Administración de proyectos. TK: Redacción – borrador original, Redacción – revisión y edición, Curación de datos, Análisis formal, Investigación, Metodología, Visualización. GS-R: Redacción – borrador original, Redacción – revisión y edición, Conceptualización, Adquisición de fondos, Administración de proyectos, Supervisión, Recursos. SR: Conceptualización, Obtención de fondos, Metodología, Administración de proyectos, Supervisión, Validación, Redacción – borrador original, Redacción – revisión y edición, Recursos.
Financiación
El/los autor/es declara(n) que se recibió apoyo financiero para la investigación, autoría y/o publicación de este artículo. Este estudio contó con el apoyo de una beca de investigación de la Oficina Federal de Seguridad Alimentaria y Veterinaria (FSVO) y la Oficina Federal de Agricultura (FOAG); Número de subvención: 1.18.14TG. La agencia de financiación no influyó en los resultados de la investigación ni en la publicación.
Reconocimientos
Los autores agradecen a Sara Schärrer de la Oficina Federal de Seguridad Alimentaria y Veterinaria (FSVO) por su ayuda en la extracción y seudonimización de los datos.
Conflicto de intereses
TK y SR fueron empleados por Identitas AG.
El resto de los autores declaran que la investigación se llevó a cabo en ausencia de relaciones comerciales o financieras que pudieran interpretarse como un potencial conflicto de intereses.
Nota del editor
Todas las afirmaciones expresadas en este artículo son únicamente las de los autores y no representan necesariamente las de sus organizaciones afiliadas, ni las del editor, los editores y los revisores. Cualquier producto que pueda ser evaluado en este artículo, o afirmación que pueda hacer su fabricante, no está garantizado ni respaldado por el editor.
Referencias
1. Thomann, B, Würbel, H, Kuntzer, T, Umstätter, C, Wechsler, B, Meylan, M, et al. Desarrollo de un método basado en datos para evaluar la salud y el bienestar de las especies ganaderas más comunes en Suiza: el proyecto de salud animal inteligente. Veterinario delantero Sci. (2023) 10:1125806. doi: 10.3389/fvets.2023.1125806
2. Gebhardt-Henrich, SG, y Schlapbach, K. Wie wohl fühlen sich Masthühner? Erfassung und Bewertung von Daten zu Tiergesundheit und Tierwohl [¿Cómo se sienten los pollos de engorde? Assessment and evaluation of animal health and welfare] En: M. Erhard y E. Rauch, editores. 52. Internationale Arbeitstagung Angewandte Ethologie bei Nutztieren. Darmstadt: Kuratorium für Technik und Bauwesen in der Landwirtschaft e.V. (KTBL) (2020). 223–34.
3. Lutz, B, Zwygart, S, Thomann, B, Stucki, D, y Burla, J. La relación entre los indicadores comunes basados en datos y el bienestar de los rebaños lecheros suizos. Veterinario delantero Sci. (2022) 9:991363. doi: 10.3389/fvets.2022.991363
4. Lutz, B, Zwygart, S, Rufener, C, Burla, J, Thomann, B, y Stucki, D. Variables basadas en datos utilizadas como indicadores del bienestar de las vacas lecheras a nivel de granja: una revisión. Animales. (2021) 11:3458. doi: 10.3390/ani11123458
5. Zufferey, R, Minnig, A, Thomann, B, Zwygart, S, Keil, N, Schüpbach, G, et al. Indicadores basados en animales para la evaluación del bienestar en la explotación ovina. Animales. (2021) 11:2973. doi: 10.3390/ani11102973
6. Minnig, A, Zufferey, R, Thomann, B, Zwygart, S, Keil, N, Schüpbach-Regula, G, et al. Indicadores basados en animales para la evaluación del bienestar en la granja en cabras. Animales. (2021) 11:3138. doi: 10.3390/ani11113138
7. Zwygart, S, Lutz, B, Thomann, B, Stucki, D, Meylan, M, y Becker, J. Evaluación de los indicadores de bienestar basados en datos de candidatos para terneros en Suiza. Veterinario delantero Sci. (2024) 11:1436719. doi: 10.3389/fvets.2024.1436719
8. Stachowicz, J, y Umstätter, C. Übersicht über kommerziell verfügbare digitale Systeme in der Nutztierhaltung. Transferencia de Agroscope. (2020) 294:1–28. doi: 10.34776/at294g
9. Stachowicz, J y Umstätter, C. Ausgewählte digitale Technologien für die Erhebung gesundheitsrelevanter Indikatoren von Schweinen, Milchkühen und Mastkälbern. Transferencia de Agroscope. (2021) 381:1–8. doi: 10.34776/at381g
10. Stachowicz, J, y Umstätter, C. ¿Detectamos automáticamente los problemas relacionados con la salud o el bienestar general? Un marco de trabajo. Proc R Soc B Biol Sci. (2021) 288:20210190. doi: 10.1098/rspb.2021.0190
11. Wolfert, S, Ge, L, Verdouw, C, y Bogaardt, M-J. Big data en la agricultura inteligente: una revisión. Agric Syst. (2017) 153:69–80. doi: 10.1016/j.agsy.2017.01.023
12. Cockburn, M. Revisión: aplicación y discusión prospectiva del aprendizaje automático para la gestión de granjas lecheras. Animales. (2020) 10:1690. doi: 10.3390/ani10091690
13. Schärrer, S, Widgren, S, Schwermer, H, Lindberg, A, Vidondo, B, Zinsstag, J, et al. Evaluación de los parámetros a nivel de explotación derivados de los movimientos de animales para su uso en programas de vigilancia del ganado en Suiza basados en el riesgo. BMC Vet Res. (2015) 11:149. doi: 10.1186/s12917-015-0468-8
14. Schirdewahn, F, Lentz, HHK, Colizza, V, Koher, A, Hövel, P, y Vidondo, B. Alerta temprana de brotes de enfermedades infecciosas en las redes de transporte de ganado. PLoS Uno. (2021) 16:e0244999. doi: 10.1371/journal.pone.0244999
15. FOAG. Política agrícola. Oficina Federal de Agricultura. (2021). Disponible en: https://www.blw.admin.ch/blw/en/home/politik/agrarpolitik.html (consultado el 25 de octubre de 2023).
16. Anónimo. Ley de enfermedades animales (ETG). La Asamblea Federal de la Confederación Suiza. (2023). Disponible en: https://www.fedlex.admin.ch/eli/cc/1966/1565_1621_1604/de (consultado el 25 de octubre de 2023).
17. Anónimo. Ordenanza sobre sistemas de información para el servicio público veterinario (ISVet-V). La Asamblea Federal de la Confederación Suiza. (2019). Disponible en: https://www.fedlex.admin.ch/eli/oc/2018/708/de (consultado el 25 de octubre de 2023).
18. Consejo Federal, Suiza. Estrategia sobre la resistencia a los antibióticos StAR. (2015). Disponible en: https://www.star.admin.ch/star/en/home.html (consultado el 25 de octubre de 2023).
19. Anónimo. Ordenanza de Subvenciones Directas (DZV). La Asamblea Federal de la Confederación Suiza. (2021). Disponible en: https://www.fedlex.admin.ch/eli/oc/2021/682/de (consultado el 25 de octubre de 2023).
20. Lokhorst, C, de Mol, RM y Kamphuis, C. Revisión invitada: big data en la ganadería lechera de precisión. Animal. (2019) 13:1519–28. doi: 10.1017/S1751731118003439
21. Norton, T, Chen, C, Larsen, MLV y Berckmans, D. Revisión: ganadería de precisión: construcción de ‘representaciones digitales’ para acercar los animales al ganadero. Animal. (2019) 13:3009–17. doi: 10.1017/S175173111900199X
22. Verdouw, C, Tekinerdogan, B, Beulens, A y Wolfert, S. Gemelos digitales en la agricultura inteligente. Agric Syst. (2021) 189:103046. doi: 10.1016/j.agsy.2020.103046
23. Botreau, R, Veissier, I, y Pern, P. Evaluación global del bienestar animal: estrategia adoptada en la calidad® del bienestar. Anim Welf. (2009) 18:363–70. doi: 10.1017/S0962728600000762
24. Friedrich, L, Krieter, J, Kemper, N y Czycholl, I. Indicadores de iceberg para el bienestar de cerdas y lechones. Sostener para. (2020) 12:8967. doi: 10.3390/su12218967
25. Heath, CAE, Browne, WJ, Mullan, S y Main, DCJ. Navegando el iceberg: reducir el número de parámetros dentro del protocolo de evaluación de la calidad® del bienestar de las vacas lecheras. Animal. (2014) 8:1978–86. doi: 10.1017/S1751731114002018
26. Losada-Espinosa, N, Estévez-Moreno, LX, Bautista-Fernández, M, Galindo, F, Salem, AZM, y Miranda-de la Lama, GC. Evaluación del bienestar del ganado a nivel de matadero: perfiles de riesgo integrados basados en el origen del animal, la logística previa al sacrificio y los indicadores iceberg. Ant: Vet Med. (2021) 197:105513. doi: 10.1016/j.prevetmed.2021.105513
27. Lasser, J, Matzhold, C, Egger-Danner, C, Fuerst-Waltl, B, Steininger, F, Wittek, T, et al. Integración de diversas fuentes de datos para predecir el riesgo de enfermedades en el ganado lechero: un enfoque de aprendizaje automático. J Anim Sci. (2021) 99:skab294. doi: 10.1093/jas/skab294
28. Matzhold, C, Lasser, J, Egger-Danner, C, Fuerst-Waltl, B, Wittek, T, Kofler, J, et al. Un enfoque sistemático para analizar el impacto de los perfiles de las explotaciones en la salud bovina. Sci Rep. (2021) 11:21152. doi: 10.1038/s41598-021-00469-2
29. Slob, N, Catal, C y Kassahun, A. Aplicación del aprendizaje automático para mejorar la gestión de las granjas lecheras: una revisión sistemática de la literatura. Ant: Vet Med. (2021) 187:105237. doi: 10.1016/j.prevetmed.2020.105237
30. Identitas, S.A. Estadística animal. (2023). Disponible en: https://tierstatistik.identitas.ch/de/ (consultado el 25 de octubre de 2023).
31. FOAG. Datenmanagement. Oficina Federal de Agricultura. (2018). Disponible en: https://www.blw.admin.ch/blw/de/home/politik/datenmanagement.html (consultado el 25 de octubre de 2023).
32. OVVV. Technische Weisung über den Tierschutz bei Rindern-Tierschutz-Kontrollhandbuch. (2021). Disponible en: https://www.blv.admin.ch/dam/blv/de/dokumente/tiere/nutztierhaltung/rinder/tsch-kontrollhandbuch-rinder.pdf.download.pdf/Tierschutz-Kontrollhandbuch-Rinder.pdf (consultado el 12 de junio de 2024).
33. OVVV. Technische Weisung über den Tierschutz bei Schweinen – Tierschutz-Kontrollhandbuch. (2021). Disponible en: https://www.blv.admin.ch/dam/blv/de/dokumente/tiere/nutztierhaltung/schweine/tsch-kontrollhandbuch-schwein.pdf.download.pdf/Tierschutz-Kontrollhandbuch-Schweine.pdf (consultado el 12 de junio de 2024).
34. OVVV. Kontrollunterlagen und -handbücher. Disponible en: https://www.blv.admin.ch/blv/de/home/tiere/rechts–und-vollzugsgrundlagen/hilfsmittel-und-vollzugsgrundlagen/kontrollhandbuecher.html (consultado el 12 de junio de 2024)
35. FOAG. Tierwohlbeiträge (BTS/RAUS). Oficina Federal de Agricultura. (2021). Disponible en: https://www.blw.admin.ch/blw/de/home/instrumente/direktzahlungen/produktionssystembeitraege23/tierwohlbeitraege1.html (consultado el 25 de octubre de 2023).
36. FOAG. Ökologischer Leistungsnachweis. Oficina Federal de Agricultura. (2021). Disponible en: https://www.blw.admin.ch/blw/de/home/instrumente/direktzahlungen/oekologischer-leistungsnachweis.html (consultado el 25 de octubre de 2023).
37. Anónimo. Tierseuchenverordnung. (1995). Disponible en: https://fedlex.data.admin.ch/eli/cc/1995/3716_3716_3716 (consultado el 17 de junio de 2024).
38. Anónimo. Merkblatt über die amtliche Abortüberwachung bei Klauentieren. (2021). Disponible en: https://www.blv.admin.ch/dam/blv/de/bilder/home-blv/tiere/tiergesundheit/merkblatt-abortueberwachung-klauentiere.pdf.download.pdf/Merkblatt%20Tierärzte_Amtliche%20Abortüberwachung_d.pdf (consultado el 17 de junio de 2024).
39. Anónimo. Tierschutzverordnung. (2008). Disponible en: https://fedlex.data.admin.ch/eli/cc/2008/416 (consultado el 17 de junio de 2024).
40. Anónimo. Ley de Bienestar Animal. La Asamblea Federal de la Confederación Suiza. (2005). Disponible en: https://fedlex.data.admin.ch/filestore/fedlex.data.admin.ch/eli/cc/2008/414/20170501/en/pdf-a/fedlex-data-admin-ch-eli-cc-2008-414-20170501-en-pdf-a.pdf
41. Anónimo. Verordnung des BLV über die Haltung von Nutztieren und Haustieren. Oficina Federal de Seguridad Alimentaria y Veterinaria. (2008). Disponible en: https://fedlex.data.admin.ch/eli/cc/2008/610 (consultado el 17 de junio de 2024).
42. Anónimo. Verordnung über die Direktzahlungen an die Landwirtschaft (DZV). La Asamblea Federal de la Confederación Suiza. (2013). Disponible en: https://fedlex.data.admin.ch/eli/cc/2013/765 (consultado el 17 de junio de 2024).
43. Tavenard, R, Faouzi, J, Vandewiele, G, Divo, F, Androz, G, Holtz, C, et al. Tslearn, un kit de herramientas de aprendizaje automático para datos de series temporales. J Mach Aprender Res. (2020) 21:1–6. Disponible en: https://jmlr.csail.mit.edu/papers/v21/20-091.html.
44. HeiGIT. Openrouteservice. (2023). Disponible en: openrouteservice.org (consultado el 25 de octubre de 2023).
45. Pedregosa, F, Varoquaux, G, Gramfort, A, Michel, V, Thirion, B, Grisel, O, et al. Scikit-learn: aprendizaje automático en Python. J Mach Aprender Res. (2011) 12:2825–30. Disponible aaaa http://www.jmlr.org/papers/volume12/pedregosa11a/pedregosa11a.pdf aa
Palabras clave: basado en datos, bosque aleatorio, sanidad animal, bienestar animal, monitoreo
Cita: Thomann B, Kuntzer T, Schüpbach-Regula G y Rieder S (2024) Investigación del uso de algoritmos de aprendizaje automático para respaldar las inspecciones de bienestar animal basadas en el riesgo de las granjas de ganado y cerdos. Frente. Vet. Sci. 11:1401007. doi: 10.3389/fvets.2024.1401007
Editado por:
Bouda Vosough Ahmadi, Organización de las Naciones Unidas para la Alimentación y la Agricultura, Italia
Revisado por:
Temple Grandin, Universidad Estatal de Colorado, Estados
Unidos Enfermera Ozturk, Universidad de Estambul-Cerrahpasa, Türkiye
Derechos de autor © 2024 Thomann, Kuntzer, Schüpbach-Regula y Rieder. Este es un artículo de acceso abierto distribuido bajo los términos de la Licencia Creative Commons Attribution License (CC BY).
*Correspondencia: Stefan Rieder, stefan.rieder@identitas.ch; Vencer a Thomann, beat.thomann@unibe.ch
‡ORCID: Venció a Thomann, https://orcid.org/0000-0002-8956-2231
Thibault Kuntzer, https://orcid.org/0000-0002-9601-8373
Gertraud Schüpbach-Regula, https://orcid.org/0000-0003-4607-5828
Stefan Rieder, https://orcid.org/0000-0002-4658-2187
†Estos autores comparten la primera autoría
Renuncia: Todas las afirmaciones expresadas en este artículo son únicamente las de los autores y no representan necesariamente a las de sus organizaciones afiliadas, o las del editor, de los editores y de los revisores. Cualquier producto que puede ser evaluada en este artículo o afirmación que puede ser hecha por su El fabricante no está garantizado ni respaldado por el editor.
Date de alta y recibe nuestro 👉🏼 Diario Digital AXÓN INFORMAVET ONE HEALTH
Date de alta y recibe nuestro 👉🏼 Boletín Digital de Foro Agro Ganadero
Noticias animales de compañía
Noticias animales de producción
Trabajos técnicos animales de producción
Trabajos técnicos animales de compañía